本文主要来源于Expressive TTS(01)。
Expressive TTS是目前语音合成领域中比较活跃的方向,它和单纯TTS的区别是,它更关注合成声音的风格(例如新闻播报,讲故事,解说)、情感(例如生气,兴奋,悲伤)、韵律(例如重读,强调、语调)等等。自从深度学习技术大放异彩后,语音合成模型在合成声音的自然度方面有了极大的提高(例如Tacotron,Tacotron2,WaveNet),跳词复读的问题也在最近得到了解决(例如DurIAN,FastSpeech),而深度学习不仅可以让语音的自然度得到大幅度的提升,对一些难以显式建模的特征上也有很强大的学习能力,因此,让语音合成能更加具有expressive成为了一个研究热点。
第一篇:Uncovering Latent Style Factors for Expressive Speech Synthesis(2017)
https://arxiv.org/abs/1711.00520
这一篇是 google 的王宇轩大佬早在 2017 年上传到 arxiv 上的一篇文章,也是表现力语音合成领域可追溯到的比较早的一篇文章。
动机
理想情况下,生成的语音应该传达正确的信息(可理解性 intelligibility),同时听起来像人类的语言(自然性 naturalness),具有正确的语调(表现力 expressiveness)。 然而,大多数现有的合成模型如 Tacotron 仅关注前两个问题,并没有明确地对语调进行建模。尽管有重要的应用,如对话助手和长篇阅读,但富有表现力的 TTS 仍然被认为是一个重要的开放问题。
韵律变化本质上是多尺度的。音调和说话持续时间的局部变化可以传达语义,而整体音调轨迹等全局属性可以传达情绪和情感。
在这项工作中,作者引入了 “风格标记(style tokens)” 的概念,它可以被视为捕捉韵律变化的潜在变量,而单靠文本输入是无法捕捉的。
模型结构
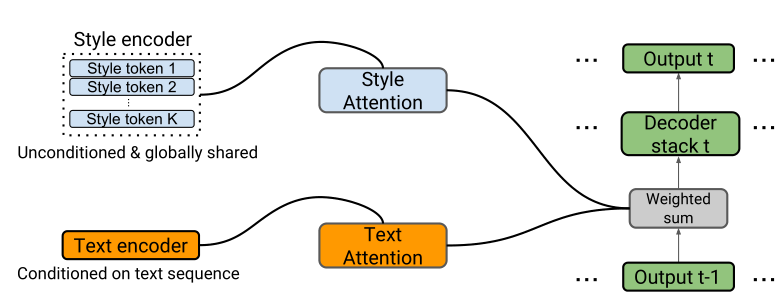
理想情况下,一个富有表现力的 TTS 模型应该允许在合成过程中明确地控制对韵律(prosody)的选择。由于 Tacotron 只将文本作为输入,为了准确地重建训练信号,它必须学会将任何韵律信息隐式地储存在它的权重中,而我们并不能明确地控制它。为了允许显式的对韵律进行控制,作者在 Tacotron 中引入了一个专门的网络组件,用一个新的风格注意力模块(style attention)来增强现有的文本编码器的注意力模块(text attention)。新的注意力模块关注一个风格编码器(style encoder),它将 K 个 “风格标记” 作为输入,并输出它们的嵌入向量来作为风格注意力模块的输入(可以简单的理解为 K 个风格标记就是 1 到 K 的数字,然后经过一个 embedding,得到 K 个一维的 embedding vector 作为 style attention 的输入)。在解码器中,通过一种加权求和的操作将来自文本注意力和风格注意力的两个上下文向量结合起来。计算 weighted 的操作作者称为一个 controller layer(在图中并未明显体现,文章提到 The weights are predicted by a single layer MLP with sigmoid outputs)。Tacotron 模型的其余部分保持不变。
作者提到 style tokens 的嵌入值是随机初始化的,并通过反向传播自动学习,它们的学习仅由解码器的重建损失指导。因此,风格标记本身的学习是完全无监督的。
为什么使用基于注意力的风格标记呢?
首先,注意力有助于学习整体韵律风格的解耦(decomposition),鼓励产生具有独立韵律风格的可解释 tokens。这类似于学习一个风格原子的字典,可以结合起来重现整体风格(举个例子:每个原子都有自己的一个风格如 A 原子语速快、B 原子音调高,将 AB 原子组合起来可能能够产生一种听起来生气的情绪(即合成的语音语速又快音调又高))。
此外,注意力机制在解码器的时间分辨率上学习风格标记的组合,这使得时间变化的韵律操作成为可能。(简单的理解为就是比如说在生成一句长时间语音的时候,某个时刻可能音调高,某个时刻可能语速快些,从而生成的这一段语音在时间维度上可以组合不同的风格标记)。
为什么这种方式能够在合成语音的时候实现可控性(controllability)呢?
源自于风格编码器和文本编码器之间的一个重要区别。文本编码器是以输入的文本序列为条件的,而风格编码器则不需要输入,所有的训练序列都共享 tokens。换句话说,风格编码器计算的是训练集的先验 prior,而文本编码器计算的是后验 posteriors(以单个输入序列为条件)。这种设计允许风格标记捕捉与文本无关的韵律变化,这使得推理中的可控性得以实现。
实验
为了合成特定风格的语音,作者将所选风格标记的嵌入向量广播式地添加到完整的风格嵌入矩阵 style embedding matrix 中,从而使合成的语音偏向于指定风格。同样,可以通过连续广播添加或线性内插风格嵌入向量来混合不同的风格。
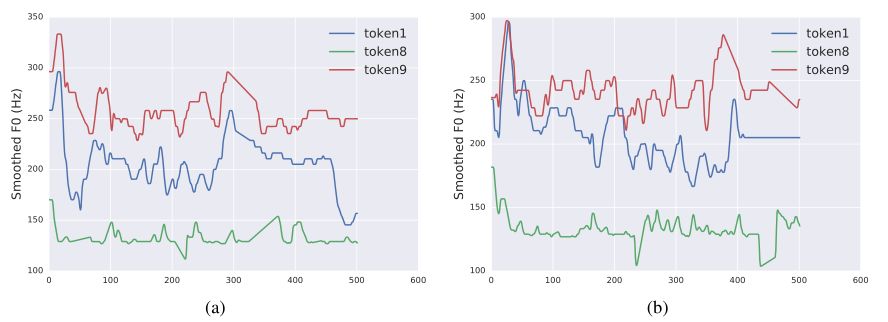
从图 2 中可以看出,”token 1” 大致对应于具有正常音高范围的马虎、草率(sloppy)风格,”token 8” 大致对应于机器人声音的风格,而 “token 9” 大致对应于高音调声音。这些风格在一定程度上反映在平滑的 F0 轨迹上。例如,”token 9” 倾向于比其他两个有更高的音调,而 “token 8” 的音调轨迹则保持平缓和低沉。同样的趋势可以从图 2(b) 中看出,该图是由不同的语句产生的,表明风格标记的运作独立于文本输入。
结论
本文提出的风格标记(style tokens)可以在无监督的情况下学习,不需要注释的标签。在 Tacotron 模型中实现了风格标记,并证明它们确实对应于不同的声音风格因素,通过在推理中指定所需的风格来实现某种程度的声音控制。
第二篇: Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis(2018)
https://arxiv.org/abs/1803.09017
这一篇是王大佬接第一篇的续作,在这一篇文章中王大佬正式提出了 GSTs(global style tokens)的概念。
动机
韵律 prosody 是语音中一些现象的汇合,如副语言信息、语调 intonation、重音 stress 和风格 style。这篇文章主要关注 style modeling,它的目标是为模型提供一种能力,这种能力能够为给定内容选择一种说话风格。风格包含丰富的信息,如意图和情感,并影响说话人对语调和语速的选择。适当的风格呈现会影响整体感知。
风格建模 style modeling 有如下几个挑战:
- 对 “正确的” 声音风格没有客观的衡量标准,这使得建模和评估都很困难。获取大型数据集的注释可能成本很高,而且同样存在问题,因为人类评分者经常会有分歧。
- 富有表现力的声音的高动态范围(如音调的高低起伏大)很难建模。许多 TTS 模型,包括最近的端到端系统,只在其输入数据上学习平均的声调分布(因为输入只有文本信息,不包含声学信息),产生的语音尤其是长句子的表现力较差。并且,它们往往缺乏控制语音合成的表达方式的能力。
模型结构

- 训练期间:
1)参考编码器 reference encoder,将可变长度的音频序列的 prosody 压缩成一个固定长度的向量,称之为 reference embedding。在训练期间,参考音频是真实音频。
reference encoder 架构的细节:输入 log-mel spectrogram ——> 6*(2DConv+Batch Norm+ReLU) ——>reshape 3 dimensions (保留时间维度,将 channel 和 freq reshape 成一维,即 [batch_size, channel, freq, time]——>[batch_size, channel*freq, time]) ——>single layer unidirectional GRU (128 unit) ——> 输出:reference embedding (the last GRU state)。
2)reference embedding 被传递到一个风格标记层 style token layer,在那里它被用作注意力模块的查询向量。注意,这里的注意力不是用来学习对齐的。相反,它学习 referensce embedding 和随机初始化的嵌入库中 (a bank of randomly initialized embeddings) 的每个 token 之间的相似性测量。这组嵌入被称之为全局风格标记 global style tokens (GSTs) 或标记嵌入 token embeddings,在所有训练序列中共享。
3) 注意力模块输出一组组合权重,代表每个 style token 对 referensce embedding 的贡献。GSTs 的加权总和被称之为风格嵌入 style embedding,在每个时间段被传递给文本编码器进行调节。
style token layer 由 10 (实验发现 10 个足以代表训练数据中小而丰富的韵律维度) 个 style token embeddings (为了和 text encoder 匹配,所以维度是 256D) 和一个 multi-head attention 组成。输入 reference embedding(128D) 和 style token embeddings(256D) ——> multi-head attention ——> 输出 style embedding (256D)。最后将 style embedding 加到对应的 text encoder states 上。
4)style token layer 与模型的其他部分共同训练,只由 Tacotron 解码器的重建损失驱动。因此,GSTs 不需要任何明确的风格或韵律标签。
- 推理期间:
1)可以直接将文本编码器限定在某些标记上,如图 3 推理模式图的右侧所描述的(”以 tokenB 为条件”)。这允许在没有参考音频的情况下进行风格控制和操作。
2)可以输入一个不同的音频(其对应的文本内容不需要与要合成的文本相同)来实现风格转移。这在图 3 的推理模式图的左侧被描绘出来(”以音频为条件”)。
总的来说,GSTs 模型可以被认为是一种将 reference embedding 分解为一组基础向量或 style token embedding 的端到端方法。GSTs 层在概念上与 VQ-VAE 编码器有些类似,因为它学习了其输入的量化表示。感觉用 VQ-VAE 来做 reference embedding 的解耦也可以,但是作者说实验效果很差。
GSTs embeddings 也可以被看作是一个外部存储器,存储从训练数据中提取的风格信息。参考信号在训练时指导记忆的写入,在推理时指导记忆的读取。
实验
感兴趣的可以点击上边这个链接听一下文章提供的 Audio samples。
结论
这项工作介绍了 GSTs。GSTs 是直观的,不需要明确的标签就能学习。当对富有表现力的语音数据进行训练时,GSTs 模型会产生可解释的嵌入 embeddings,可用于控制 control 和转移风格 transfer style。
然而,在实验中也发现了一些问题,比如并非所有的 single-token 都能捕捉到单一的属性:虽然一个 token 可能学会了代表说话速度,但其他 tokens 可能学会了反映训练数据中风格共现的混合属性(例如,一个低音调的 token 也能编码较慢的说话速度)。探索更多独立的风格属性学习(可以理解为解耦的更彻底)仍是目前工作的一个重点。
第三篇: Learning latent representations for style control and transfer in end-to-end speech synthesis(2019)
Learning latent representations for style control and transfer in end-to-end speech synthesis
动机
VAE 有很多优点,如学习分解因素、平滑插值或在潜在表征 latent representation 之间连续取样,可以获得可解释的同(重)构体。
最主要的就是,VAE 可以很容易地得到解耦 disentangle 之后的 latent code,每个 latent code 的维度都可以代表一个特定的概念,通过调整某个概念的值,我们就能控制特定的概念。比如在 image synthesis 中,调整特定维度的 latent code 就可以控制合成出来的物体的角度、大小等特定概念。
直观地说,在语音合成中,说话人的潜在状态 latent state,如 affect 和意图 intent,有助于形成韵律 prosody、情感 emotion 或说话风格 speaker style。latent state 所起的作用与 VAE 中的潜在表征 latent representation 相当相似。因此,本文将 VAE 引入 Tacotron2,以学习说话人状态在连续空间中的潜态表示,并进一步控制语音合成中的说话风格。
模型结构
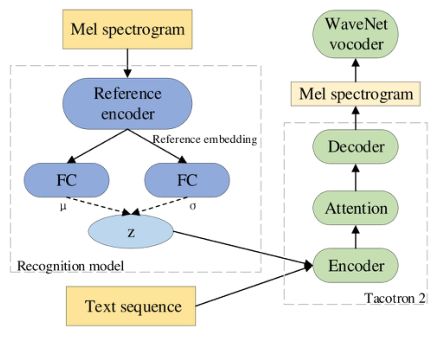
如图 4 所示,整个网络结构由两部分组成,(1) 识别模型或推理网络,它将参考音频编码为固定长度的潜在表示(潜在表征 z 代表风格表示);(2)一个基于 Tacotron2 的端到端 TTS 模型,它将综合的编码器状态(包括潜在表征和文本编码器状态)转换为具有特定风格的目标句。
识别模型架构的细节(其中 reference encoder 和第二篇一致):输入 mel spectrogram ——> 6*(2DConv+Batch Norm+ReLU) ——>reshape 3 dimensions (保留时间维度,将 channel 和 freq reshape 成一维,即 [batch_size, channel, freq, time]——>[batch_size, channel*freq, time]) ——>a GRU ——> 输出:reference embedding (the last GRU state) ——> 两个单独的全连接层 + linear activation function——> 输出:均值和方差 ——> 重采样 reparameterization ——>输出:z。
输出的 text encoder state 加上 z(先经过一个 linear layer 调整一下维度)被送到 Tacotron2 的 decoder 中。

损失函数 loss 为 VAE 的损失 (其中重构损失选择 L2-loss)+ $l_{stop}$ (stop token loss)。
KL collapse problem
所谓 KL collapse problem 是指在训练过程中 KL loss 下降得比其它 loss 都快从而造成 KL loss 很快收敛到 0 并不再上升,这会造成 encoder 无法继续训练。因此作者使用了 KL annealing 来解决这个问题,具体来说,首先用一个动态调整的 weight 来控制 KL loss 的训练强度,其次是减少 KL loss 的训练次数,即每隔 K 个 step 才训练一次 KL loss。
1 | def kl_anneal_function(self, anneal_function, lag, step, k, x0, upper): |
实验
在推理阶段,在 style control 评估中,直接操作 z,不需要经过整个识别模型。在 style transfer 的评估中,需要把音频片段作为参考,并通过识别模型。 Parallel transfer 意味着目标文本信息与参考音频的相同,反之 non-parallel style transfer 意味着目标文本信息与参考音频的不同。
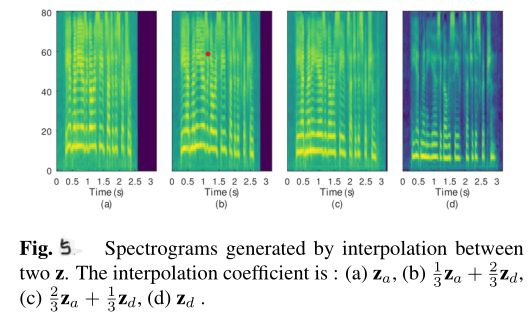
如图 5 所示,这两个 z 是通过向识别模型提供两个参考音频而得到的, $z_a$表示说话语速快和高音调, $z_d$表示说话语速慢和低音调。通过对这两个 z 的插值 interpolation 操作,可以看到生成的语音的音高和语速都在逐渐下降。这一结果表明,学习到的潜在空间在控制声谱图的趋势方面是连续的,这将进一步反映在风格的变化上。
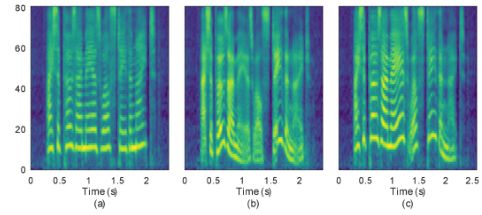
一个解耦过的表征(也就是 z)意味着一个潜在变量(也就是其中的一个维度或者值)能够完全单独控制一个概念,并且对其他因素的变化没有影响。从图 6 可以看出,通过操纵单一维度而固定其他维度对声谱图的改变,调整其中一个维度,生成的语音只有一个属性发生变化,如 z 的几个维度可以分别控制着合成语音的音高、局部音调的变化、语速等风格属性。这表明,在这个模型中,VAE 具有学习解耦 latent state 的能力。
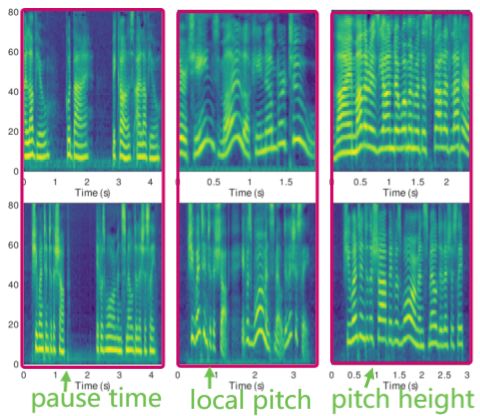
从图 7 可以看出,生成的声谱图和参考的声谱图具有相似的属性。
结论
本文提出了 VAE+Tacotron2 来对生成的语音进行控制,最终得到了与 GSTs 模型相似的效果。

